More or less since 2008 it's been popular to criticise the focus on GDP per capita as a public policy mistake, and a resurgence of scepticism about economics more generally as being unconcerned with the things that 'actually matter'.
Intuitively I can see why people might conclude that measuring total economic activity, which is what GDP is, would not be the best way to guide public policy. And for sure, there are lots of valid criticisms of GDP, especially when one digs into some specific area or other. But quite often those issues end up being about how the measure is used politically rather than as a purely economic proxy measure of national success (broadly defined). And as it probably goes without saying, any single measure one might pick to summarise the general state of economic or personal well-being would have all kinds of potential problems with it and would end up getting used as a political football.
Anyway, broadly there are three big criticisms: 1) GDP is hopelessly flawed as a measure of human welfare because it excludes nasty things like pollution and includes things like spending on prisons. 2) Even if GDP and economic well-being were correlated, GDP ignores distribution/inequality. 3) More fundamentally, a higher material standard of living does not make people happier, so we should focus more directly on policy that does.
1) Here, the question is simple: GDP may not be something we directly care about, but is it correlated to things we do? And the basic fact is that it is surprisingly well correlated to lots and lots of things we should definitely care about. When you do cross-country comparisons one sees a strong positive relationship between GDP and the following (not an exhaustive list): infant mortality, life expectancy, education, and violence.
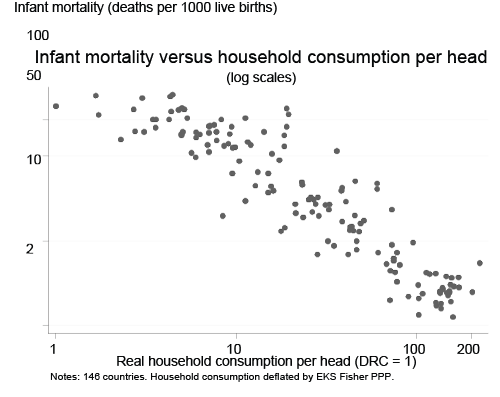
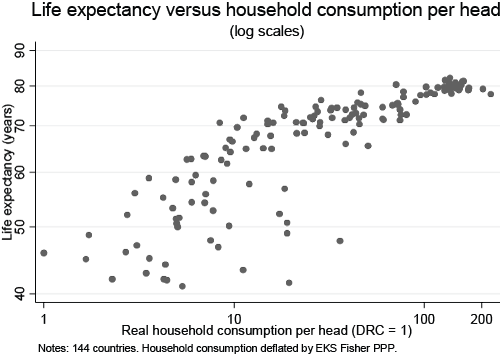
Now, correlation is not causation of course, and there are various exceptions, but if what we're looking for is a single number that can give us a snapshot of a much wider picture, GDP doesn't do a bad job at all.
2) True, though again in cross-country comparisons there's a negative correlation between GDP per capita and inequality - as unequal as the US is, it's nothing like as bad as Brazil, or South Africa, or India.
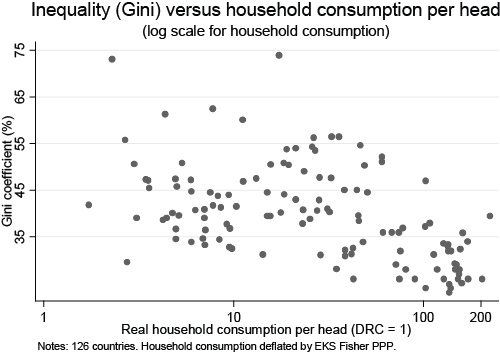
That said, I think inequality is a massive problem, both economically and politically, and to the degree that focus on GDP means we don't address inequality (because it's politically convenient not to) it's a concern. But I don't think one could argue it's a cause.
3) There are a few difficulties here. The biggest being that the data is opaque and sometimes contradictory. What we know for sure is that reliable measures of well-being and happiness go up in line with economic wealth to a certain point - about $100K per year per household in the US and then the correlation seems to partially break down and become more about how wealthy people feel in comparison to their peers (aka it becomes about relative status). The reasoning seems to be that money can buy real well-being improvements like health and security up to a certain level, but beyond that the extra spending isn't really on anything fundamental. A wider issue, drawing on the psychology literature, is what's known as 'hedonic adaptation', which basically means that ones long term experience of well-being is largely derived from intrinsic things and thus if you experience a boost in extrinsic factors - eg you get richer - your reported well-being goes up for a while, but mostly returns to it's previous levels after 6 months. The extreme example is comparing the reported well-being of people who experience a major life changing event, for example someone who loses a leg vs someone who wins the lottery. Within 6 months, both on average have returned to their pre-event levels of reported happiness. All of which is to say, linking individual happiness to economics might not be totally straight forward. But the relationship is no less fraught that with anything we might make public policy about.
All in all, GDP isn't perfect, but it's not as bad as people think. There is a wider question about GDP and climate change, which I plan to deal with in my next essay. So stay tuned for that.
Intuitively I can see why people might conclude that measuring total economic activity, which is what GDP is, would not be the best way to guide public policy. And for sure, there are lots of valid criticisms of GDP, especially when one digs into some specific area or other. But quite often those issues end up being about how the measure is used politically rather than as a purely economic proxy measure of national success (broadly defined). And as it probably goes without saying, any single measure one might pick to summarise the general state of economic or personal well-being would have all kinds of potential problems with it and would end up getting used as a political football.
Anyway, broadly there are three big criticisms: 1) GDP is hopelessly flawed as a measure of human welfare because it excludes nasty things like pollution and includes things like spending on prisons. 2) Even if GDP and economic well-being were correlated, GDP ignores distribution/inequality. 3) More fundamentally, a higher material standard of living does not make people happier, so we should focus more directly on policy that does.
1) Here, the question is simple: GDP may not be something we directly care about, but is it correlated to things we do? And the basic fact is that it is surprisingly well correlated to lots and lots of things we should definitely care about. When you do cross-country comparisons one sees a strong positive relationship between GDP and the following (not an exhaustive list): infant mortality, life expectancy, education, and violence.
Now, correlation is not causation of course, and there are various exceptions, but if what we're looking for is a single number that can give us a snapshot of a much wider picture, GDP doesn't do a bad job at all.
2) True, though again in cross-country comparisons there's a negative correlation between GDP per capita and inequality - as unequal as the US is, it's nothing like as bad as Brazil, or South Africa, or India.
That said, I think inequality is a massive problem, both economically and politically, and to the degree that focus on GDP means we don't address inequality (because it's politically convenient not to) it's a concern. But I don't think one could argue it's a cause.
3) There are a few difficulties here. The biggest being that the data is opaque and sometimes contradictory. What we know for sure is that reliable measures of well-being and happiness go up in line with economic wealth to a certain point - about $100K per year per household in the US and then the correlation seems to partially break down and become more about how wealthy people feel in comparison to their peers (aka it becomes about relative status). The reasoning seems to be that money can buy real well-being improvements like health and security up to a certain level, but beyond that the extra spending isn't really on anything fundamental. A wider issue, drawing on the psychology literature, is what's known as 'hedonic adaptation', which basically means that ones long term experience of well-being is largely derived from intrinsic things and thus if you experience a boost in extrinsic factors - eg you get richer - your reported well-being goes up for a while, but mostly returns to it's previous levels after 6 months. The extreme example is comparing the reported well-being of people who experience a major life changing event, for example someone who loses a leg vs someone who wins the lottery. Within 6 months, both on average have returned to their pre-event levels of reported happiness. All of which is to say, linking individual happiness to economics might not be totally straight forward. But the relationship is no less fraught that with anything we might make public policy about.
All in all, GDP isn't perfect, but it's not as bad as people think. There is a wider question about GDP and climate change, which I plan to deal with in my next essay. So stay tuned for that.












